Hierarchical Bayesian Modeling of the English Premier League
This notebook contains the description and results of a model predicting score differences in English Premier League games using a State Space model. The English Premier League contains 20 teams, which play each other home and away. The team strengths of these teams are modeled over the course of a season using state space methods. Using team strengths predictions for score differences are made for each game.
Preparing the data
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import pystan
In order to get team strength ratings at the beginning of the season, points totals from the previous season are used. The points are normalized to a scale of (-1, 1), with the highest points scoring team getting a score of 1 and the lowest team getting -1. Since the bottom three teams are relegated and replaced by three promoted teams from the lower division, there are three teams in our dataset which are all given a score of -1.
The data used for the model is game by game results taken from http://www.football-data.co.uk/
This data is used to prepare a data dictionary that is fed to the stan model. This dictionary contains all the variables used by the model.
p = pd.read_csv('prevseason.csv', header = None)
max_s = max(p[1])
min_s = min(p[1])
p['score'] = 2*p[1]/(max_s - min_s) - (max_s + min_s)/(max_s - min_s)
def prepare_data(filename):
f = pd.read_csv('E02017.csv', dayfirst = True)
f = f[['Date', 'HomeTeam', 'AwayTeam', 'FTHG', 'FTAG', 'B365H', 'B365D', 'B365A']]
f['p_home'] = (1/f['B365H'])
f['score_diff'] = f['FTHG'] - f['FTAG']
data_dict = {}
Teams = []
data_dict['teams'] = list(f['HomeTeam'].unique())
for i in data_dict['teams']:
Teams.append(i)
data_dict['nteams'] = f['HomeTeam'].nunique()
data_dict['ngames'] = len(f['score_diff'])
data_dict['nweeks'] = int(np.floor(2*data_dict['ngames']/data_dict['nteams']))
for g in range(0, data_dict['ngames'] ):
f.loc[g, 'home_week'] = sum(f.loc[0:g, 'HomeTeam'] == f.loc[g, 'HomeTeam']) + \
sum(f.loc[0:g, 'AwayTeam'] == f.loc[g, 'HomeTeam'])
f.loc[g, 'away_week'] = sum(f.loc[0:g, 'AwayTeam'] == f.loc[g, 'AwayTeam']) + \
sum(f.loc[0:g, 'HomeTeam'] == f.loc[g, 'AwayTeam'])
data_dict['home_week'] = f['home_week'].astype('int')
data_dict['away_week'] = f['away_week'].astype('int')
data_dict['home_team'] = []
data_dict['away_team'] = []
data_dict['score_diff'] = []
for g in range(0, data_dict['ngames'] ):
data_dict['home_team'].append(1 + Teams.index(f.loc[g, 'HomeTeam']))
data_dict['away_team'].append(1 + Teams.index(f.loc[g, 'AwayTeam']))
data_dict['score_diff'].append(f.loc[g, 'score_diff'])
data_dict['prev_strength'] = np.zeros(len(Teams))
for i in range(len(p[0])):
if p[0][i] in Teams:
data_dict['prev_strength'][Teams.index(p[0][i])] = p.loc[i, 'score']
else:
data_dict['prev_strength'][i] = -1
return f, data_dict, Teams
f, data_dict, Teams = prepare_data('E02017.csv')
Description of the Stan model
The model takes in the following variables:
Number of teams (nteams)
Number of games (ngames)
Number of game weeks (nweeks)
Week number for the team playing at home (home_week)
Week number for the team playing away (away_week)
Base ratings for each team based on previous season’s performance (prev_strength)
These variables are used to determine the team strength rating, which is then used to predict score differences.
The team strength rating for team i in week w is modeled as a Gaussian random walk.
The team strength rating for week 1 is taken using the previous season’s points total and modeled as:
Using this rating we model score difference in game j as follows: $ y_{j} \sim studentt(\nu, a_{homeweek(i), hometeam(i)} - a_{awayweek(i), awayteam(i)} + b_{home}, \sigma_y) $
$ \sigma_{a,i} $ models the week by week variance from team ability in the previous week. The prior for $\sigma_{a,i} $ is
prevceof and $\sigma_{a0}$ are both given weakly informative priors of N(0,5)
model = """
data {
int<lower=1> nteams; // total number of teams
int<lower=1> ngames; // total number of games
int<lower=1> nweeks; // total number of weeks
int<lower=1> home_week[ngames]; // week number for the home team
int<lower=1> away_week[ngames]; // week number for the away team
int<lower=1, upper=nteams> home_team[ngames]; // home team ID
int<lower=1, upper=nteams> away_team[ngames]; // away team ID
vector[ngames] score_diff; // homegoals - awaygoals
row_vector[nteams] prev_strength;
}
parameters {
real prev_coef;
real alpha; // baseline home strength
real<lower=0> sigma_a0; // variance in team ability between seasons
real<lower=0> tau_a; // game to game variation
real<lower=1> nu; // t-dist degree of freedom
real<lower=0> sigma_scorediff; // variance in score_diff
row_vector<lower=0>[nteams] sigma_a_base; // game by game variation
matrix[nweeks, nteams] eta_a; // random variation
}
transformed parameters {
matrix[nweeks, nteams] a; // team abilities
row_vector<lower=0>[nteams] sigma_a; //game by game variation
a[1] = prev_coef * prev_strength + sigma_a0 * eta_a[1]; // initial abilities
sigma_a = tau_a * sigma_a_base;
for (w in 2: nweeks){
a[w] = a[w-1] + sigma_a .* eta_a[w]; // evolution of abilities
}
}
model {
vector[ngames] a_diff;
// Priors
nu ~ gamma(2, 0.2);
prev_coef ~ normal(0, 1);
sigma_a0 ~ normal(0,1);
sigma_scorediff ~ normal(0,5);
alpha ~ normal(0,0.2);
sigma_a_base ~ normal(0,1);
tau_a ~ cauchy(0,1);
to_vector(eta_a) ~ normal(0,1);
// Likelihood
for (g in 1:ngames) {
a_diff[g] = a[home_week[g], home_team[g]] - a[away_week[g], away_team[g]];
}
score_diff ~ student_t(nu, a_diff + alpha, sigma_scorediff);
}
generated quantities {
vector[ngames] score_diff_rep;
for (g in 1:ngames)
score_diff_rep[g] = student_t_rng(nu, a[home_week[g], home_team[g]] - a[away_week[g], away_team[g]] + alpha, sigma_scorediff);
}
"""
Fitting the model
The model is fit after every round of 10 games. So it is refit 38 teams. The samples after fitting the model each time are collected in the 3D matrix a_samps. These samples are then used to look at the parameter estimates later on.
a_samps = np.zeros((1500, data_dict['nweeks'], data_dict['nteams']))
for w in range(1, data_dict['nweeks'] + 1):
data_w = {}
idx = w*10
data_w['nteams'] = data_dict['nteams']
data_w['home_team'] = data_dict['home_team'][0:idx]
data_w['away_team'] = data_dict['away_team'][0:idx]
data_w['score_diff'] = data_dict['score_diff'][0:idx]
data_w['home_week'] = data_dict['home_week'][0:idx]
data_w['away_week'] = data_dict['away_week'][0:idx]
data_w['ngames'] = w*10
data_w['nweeks'] = max(list(data_w['home_week']) + list(data_w['away_week']))
data_w['prev_strength'] = data_dict['prev_strength']
fit = pystan.stan(model_code= model, data=data_w, iter=750, warmup = 375, chains=4, n_jobs = 4)
samples = fit.extract(permuted = True)
for g in range((w-1)*10, w*10):
a_samps[:, data_dict['home_week'][g]-1, data_dict['home_team'][g]-1] = samples['a'][:, data_dict['home_week'][g]-1, data_dict['home_team'][g]-1]
a_samps[:, data_dict['away_week'][g]-1, data_dict['away_team'][g]-1] = samples['a'][:, data_dict['away_week'][g]-1, data_dict['away_team'][g]-1]
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:1 of 1500 iterations ended with a divergence (0.06666666666666667%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:33 of 1500 iterations ended with a divergence (2.2%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:4 of 1500 iterations ended with a divergence (0.26666666666666666%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:1 of 1500 iterations ended with a divergence (0.06666666666666667%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:4 of 1500 iterations ended with a divergence (0.26666666666666666%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:2 of 1500 iterations ended with a divergence (0.13333333333333333%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:2 of 1500 iterations ended with a divergence (0.13333333333333333%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:3 of 1500 iterations ended with a divergence (0.2%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:2 of 1500 iterations ended with a divergence (0.13333333333333333%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:5 of 1500 iterations ended with a divergence (0.3333333333333333%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:1 of 1500 iterations ended with a divergence (0.06666666666666667%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
WARNING:pystan:2 of 1500 iterations ended with a divergence (0.13333333333333333%).
WARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_7b5b78d65548580ef20038edb9a67bfe NOW.
## looking at the parameter estimates
fit
WARNING:pystan:Truncated summary with the 'fit.__repr__' method. For the full summary use 'print(fit)'
Warning: Shown data is truncated to 100 parameters
For the full summary use 'print(fit)'
Inference for Stan model: anon_model_7b5b78d65548580ef20038edb9a67bfe.
4 chains, each with iter=750; warmup=375; thin=1;
post-warmup draws per chain=375, total post-warmup draws=1500.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
prev_coef -0.11 0.02 0.36 -0.82 -0.33 -0.1 0.12 0.57 485 1.01
alpha 0.33 1.6e-3 0.08 0.18 0.28 0.34 0.38 0.48 2210 1.0
sigma_a0 0.77 9.0e-3 0.16 0.51 0.66 0.75 0.86 1.14 296 1.01
tau_a 0.04 2.4e-3 0.03 1.3e-3 0.02 0.04 0.06 0.13 214 1.01
nu 16.58 0.2 7.68 6.82 11.11 14.74 20.28 35.91 1440 1.0
sigma_scorediff 1.49 2.1e-3 0.08 1.33 1.43 1.49 1.54 1.63 1364 1.0
sigma_a_base[1] 0.76 0.01 0.58 0.04 0.31 0.63 1.08 2.18 1926 1.0
sigma_a_base[2] 0.75 0.01 0.57 0.03 0.29 0.65 1.07 2.12 1537 1.0
sigma_a_base[3] 0.79 0.01 0.58 0.03 0.33 0.67 1.12 2.17 1807 1.0
sigma_a_base[4] 0.91 0.02 0.64 0.04 0.38 0.8 1.32 2.34 1273 1.0
sigma_a_base[5] 0.76 0.02 0.62 0.02 0.28 0.61 1.1 2.31 1359 1.0
sigma_a_base[6] 0.74 0.01 0.55 0.04 0.3 0.63 1.08 1.98 1689 1.0
sigma_a_base[7] 0.79 0.02 0.59 0.03 0.31 0.68 1.15 2.17 1533 1.0
sigma_a_base[8] 0.74 0.02 0.56 0.02 0.28 0.66 1.08 2.08 1256 1.0
sigma_a_base[9] 0.76 0.02 0.59 0.02 0.31 0.64 1.11 2.17 1342 1.0
sigma_a_base[10] 0.78 0.01 0.59 0.04 0.31 0.66 1.12 2.26 1767 1.0
sigma_a_base[11] 0.73 0.01 0.58 0.02 0.28 0.57 1.04 2.17 1583 1.0
sigma_a_base[12] 0.76 0.02 0.59 0.04 0.3 0.64 1.09 2.18 1494 1.0
sigma_a_base[13] 0.79 0.02 0.6 0.04 0.3 0.67 1.12 2.2 1480 1.0
sigma_a_base[14] 0.85 0.02 0.63 0.03 0.33 0.75 1.25 2.33 1201 1.0
sigma_a_base[15] 0.78 0.01 0.61 0.03 0.3 0.64 1.14 2.28 1729 1.0
sigma_a_base[16] 0.77 0.01 0.61 0.03 0.29 0.63 1.1 2.3 1780 1.0
sigma_a_base[17] 0.77 0.02 0.58 0.04 0.31 0.67 1.11 2.16 1476 1.0
sigma_a_base[18] 0.79 0.01 0.58 0.04 0.31 0.66 1.15 2.17 1871 1.0
sigma_a_base[19] 0.79 0.02 0.61 0.02 0.31 0.67 1.1 2.34 1568 1.0
sigma_a_base[20] 0.8 0.02 0.61 0.03 0.32 0.67 1.11 2.32 1511 1.0
eta_a[1,1] 0.74 0.02 0.57 -0.38 0.37 0.73 1.09 1.87 732 1.0
eta_a[2,1] 0.01 0.02 1.02 -2.01 -0.67 0.01 0.69 2.05 2267 1.0
eta_a[3,1] 0.05 0.02 1.06 -2.0 -0.68 0.08 0.8 2.07 2534 1.0
eta_a[4,1] 0.13 0.02 1.01 -1.99 -0.53 0.15 0.81 2.12 1869 1.0
eta_a[5,1] 0.07 0.02 1.02 -1.9 -0.61 0.07 0.78 2.08 2053 1.0
eta_a[6,1] 0.06 0.02 0.97 -1.85 -0.58 0.05 0.71 1.97 2128 1.0
eta_a[7,1] 0.07 0.02 1.02 -1.86 -0.63 0.07 0.74 2.1 2492 1.0
eta_a[8,1] 0.04 0.02 1.03 -1.86 -0.7 0.02 0.79 2.14 2586 1.0
eta_a[9,1] 0.07 0.02 1.02 -1.92 -0.65 0.05 0.77 2.06 2179 1.0
eta_a[10,1] 0.02 0.03 1.06 -2.01 -0.72 0.05 0.78 2.05 1644 1.0
eta_a[11,1] 4.2e-3 0.02 1.03 -2.14 -0.63 0.02 0.67 1.93 2308 1.0
eta_a[12,1] 1.5e-4 0.02 1.02 -1.99 -0.7 0.02 0.7 1.94 1845 1.0
eta_a[13,1] -4.7e-3 0.02 1.06 -2.07 -0.71-9.7e-3 0.69 2.09 2303 1.0
eta_a[14,1] 0.01 0.02 0.99 -1.9 -0.66 0.03 0.69 1.97 2014 1.0
eta_a[15,1] -0.02 0.02 0.96 -1.89 -0.68 -0.02 0.64 1.82 2551 1.0
eta_a[16,1] -0.03 0.02 1.02 -2.06 -0.7 -0.06 0.65 1.97 2521 1.0
eta_a[17,1] -5.7e-3 0.02 1.07 -2.07 -0.73-7.4e-3 0.74 2.14 3187 1.0
eta_a[18,1] 0.02 0.02 1.01 -1.91 -0.69 0.01 0.74 1.96 2572 1.0
eta_a[19,1] -0.02 0.02 0.99 -2.01 -0.65 -0.01 0.65 1.97 2212 1.0
eta_a[20,1] -0.01 0.02 1.01 -2.03 -0.67 0.02 0.64 1.92 2515 1.0
eta_a[21,1] -0.02 0.02 0.99 -1.85 -0.72 -0.03 0.69 1.81 1910 1.0
eta_a[22,1] -1.4e-3 0.02 0.98 -1.91 -0.7 0.02 0.69 1.88 2187 1.0
eta_a[23,1] 0.04 0.02 0.97 -1.85 -0.66 0.04 0.76 1.86 2568 1.0
eta_a[24,1] 9.4e-3 0.02 1.01 -2.06 -0.68 9.2e-3 0.68 2.08 1956 1.0
eta_a[25,1] -9.3e-3 0.02 1.02 -2.04 -0.72 5.0e-3 0.69 1.98 1850 1.0
eta_a[26,1] 0.03 0.02 0.99 -1.94 -0.6 0.04 0.67 2.03 2494 1.0
eta_a[27,1] -0.01 0.02 1.02 -2.02 -0.67 -0.05 0.67 2.03 2848 1.0
eta_a[28,1] -0.01 0.02 1.02 -1.97 -0.67 -0.03 0.64 2.04 2225 1.0
eta_a[29,1] 0.03 0.02 0.99 -2.01 -0.6 0.04 0.69 1.97 2034 1.0
eta_a[30,1] 0.07 0.02 0.96 -1.77 -0.62 0.07 0.72 1.98 1684 1.0
eta_a[31,1] 0.03 0.03 0.99 -1.91 -0.62 0.03 0.68 1.94 1522 1.0
eta_a[32,1] -2.8e-3 0.02 1.02 -2.08 -0.7 -0.02 0.68 2.06 1849 1.0
eta_a[33,1] 0.01 0.02 0.99 -1.87 -0.66 1.8e-3 0.7 1.95 2269 1.0
eta_a[34,1] 0.05 0.02 1.01 -1.81 -0.69 0.03 0.74 2.12 1942 1.0
eta_a[35,1] 0.01 0.02 0.96 -1.87 -0.6 4.5e-3 0.63 1.91 2249 1.0
eta_a[36,1] 5.0e-3 0.02 0.97 -1.98 -0.61-8.8e-3 0.59 2.08 2791 1.0
eta_a[37,1] -0.05 0.02 0.98 -1.96 -0.72 -0.06 0.61 1.89 1735 1.0
eta_a[38,1] 2.7e-3 0.02 0.97 -1.89 -0.64 0.03 0.64 1.84 1747 1.0
eta_a[1,2] -0.5 0.02 0.45 -1.49 -0.8 -0.48 -0.19 0.34 864 1.0
eta_a[2,2] 8.5e-3 0.02 0.99 -1.93 -0.64 0.04 0.67 1.83 2229 1.0
eta_a[3,2] -1.6e-3 0.02 1.02 -1.98 -0.68 -0.01 0.69 1.99 2585 1.0
eta_a[4,2] -7.5e-3 0.02 0.96 -1.95 -0.66 -0.02 0.63 1.93 2109 1.0
eta_a[5,2] -0.01 0.02 1.02 -2.07 -0.7 0.01 0.68 1.99 1773 1.0
eta_a[6,2] 4.6e-3 0.02 1.01 -1.94 -0.71 0.03 0.69 2.04 2216 1.0
eta_a[7,2] -0.02 0.02 1.01 -1.99 -0.69 -0.03 0.65 1.99 2307 1.0
eta_a[8,2] 7.6e-3 0.02 0.94 -1.88 -0.63 3.1e-3 0.61 1.85 2159 1.0
eta_a[9,2] -0.03 0.02 1.0 -1.97 -0.72 -0.03 0.65 1.9 2262 1.0
eta_a[10,2] -0.06 0.02 1.02 -2.09 -0.72 -0.04 0.6 2.03 2200 1.0
eta_a[11,2] -0.04 0.02 0.92 -1.85 -0.62 -0.03 0.54 1.77 2373 1.0
eta_a[12,2] -0.1 0.02 0.97 -2.0 -0.75 -0.12 0.53 1.9 1851 1.0
eta_a[13,2] -0.05 0.02 1.01 -2.0 -0.73 -0.05 0.64 1.93 1837 1.0
eta_a[14,2] -0.08 0.02 0.97 -2.09 -0.7 -0.06 0.55 1.88 2091 1.0
eta_a[15,2] -0.08 0.02 0.97 -1.96 -0.76 -0.12 0.61 1.79 2072 1.0
eta_a[16,2] -0.06 0.02 1.03 -2.1 -0.73 -0.07 0.63 1.93 1835 1.0
eta_a[17,2] 0.03 0.02 1.02 -1.95 -0.67 0.05 0.69 2.07 2018 1.0
eta_a[18,2] -0.01 0.02 0.98 -1.95 -0.7 6.1e-3 0.64 1.78 1776 1.0
eta_a[19,2] 0.01 0.02 0.97 -1.86 -0.67-8.1e-3 0.67 1.9 2063 1.0
eta_a[20,2] 6.4e-3 0.02 0.99 -1.96 -0.63 1.2e-3 0.67 1.88 2193 1.0
eta_a[21,2] 0.01 0.02 0.99 -1.99 -0.63 -0.02 0.69 1.97 2104 1.0
eta_a[22,2] -1.8e-3 0.02 0.94 -1.93 -0.66 -0.02 0.64 1.73 1957 1.0
eta_a[23,2] 0.04 0.02 1.05 -1.97 -0.65 0.04 0.73 2.09 2446 1.0
eta_a[24,2] 3.1e-3 0.02 0.99 -1.94 -0.71 -0.01 0.71 1.92 1939 1.0
eta_a[25,2] 0.03 0.02 1.02 -2.02 -0.61 0.03 0.69 2.04 2611 1.0
eta_a[26,2] 0.03 0.02 0.98 -1.93 -0.63 0.02 0.69 1.9 2097 1.0
eta_a[27,2] -3.6e-3 0.02 0.96 -2.02 -0.63 0.01 0.65 1.75 1665 1.0
eta_a[28,2] 2.2e-3 0.02 0.98 -1.9 -0.67 -0.03 0.65 1.94 2475 1.0
eta_a[29,2] -1.8e-3 0.02 0.96 -1.88 -0.63 0.02 0.62 1.75 1814 1.0
eta_a[30,2] -0.03 0.03 0.99 -2.06 -0.71-6.9e-3 0.62 1.91 1481 1.0
eta_a[31,2] 0.01 0.02 0.98 -1.91 -0.64 -0.03 0.68 1.95 2570 1.0
eta_a[32,2] -0.02 0.02 0.97 -1.85 -0.69 -0.02 0.65 1.82 2476 1.0
eta_a[33,2] 0.03 0.02 1.0 -1.95 -0.64 3.3e-3 0.71 1.94 2239 1.0
eta_a[34,2] 0.02 0.02 1.02 -2.03 -0.66 -0.01 0.69 2.03 1870 1.0
eta_a[35,2] 0.05 0.02 1.01 -1.9 -0.64 0.06 0.73 2.08 2061 1.0
lp__ -903.6 0.82 19.64 -944.0 -916.5 -902.9 -890.2 -866.2 579 1.01
Samples were drawn using NUTS at Fri Sep 21 17:51:37 2018.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
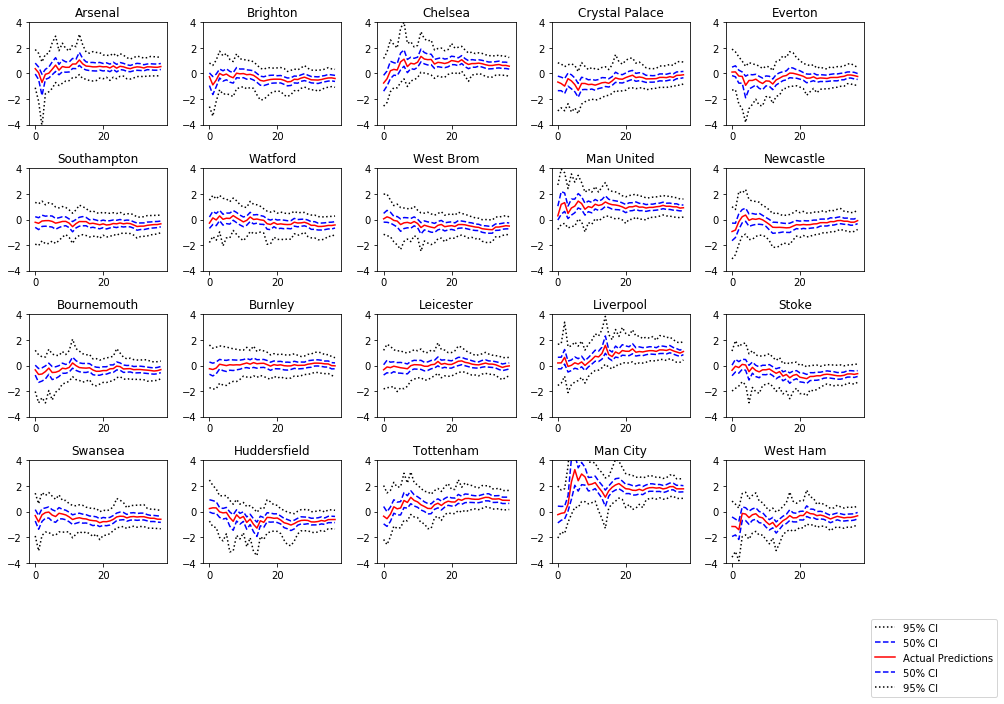
Looking at the Results of the model
The charts below show the estimated team strength ratings for all 20 teams along with their 50% and 95% confidence intervals.
plt.figure(figsize = (14,10))
for i in range(0, 20):
plt.subplot(4,5,i+1)
fit_1 = np.percentile(a_samps[:, :, i], q = [2.5, 25, 50, 75, 97.5], axis = 0)
l1, = plt.plot(range(fit_1.shape[1]), fit_1[0], 'k:', label = '95% CI')
l2, = plt.plot(range(fit_1.shape[1]), fit_1[1], 'b--', label = '50% CI')
l3, = plt.plot(range(fit_1.shape[1]), fit_1[2], 'r-', label = 'Predicted Strength')
l4, = plt.plot(range(fit_1.shape[1]), fit_1[3], 'b--', label = '50% CI')
l5, = plt.plot(range(fit_1.shape[1]), fit_1[4], 'k:', label = '95% CI')
plt.ylim(-4, 4)
plt.title(f'{Teams[i]}')
plt.legend([l1, l2, l3, l4, l5],['95% CI', '50% CI', 'Actual Predictions', '50% CI', '95% CI'],loc = 'upper right',bbox_to_anchor=(2, -0.5))
plt.tight_layout()
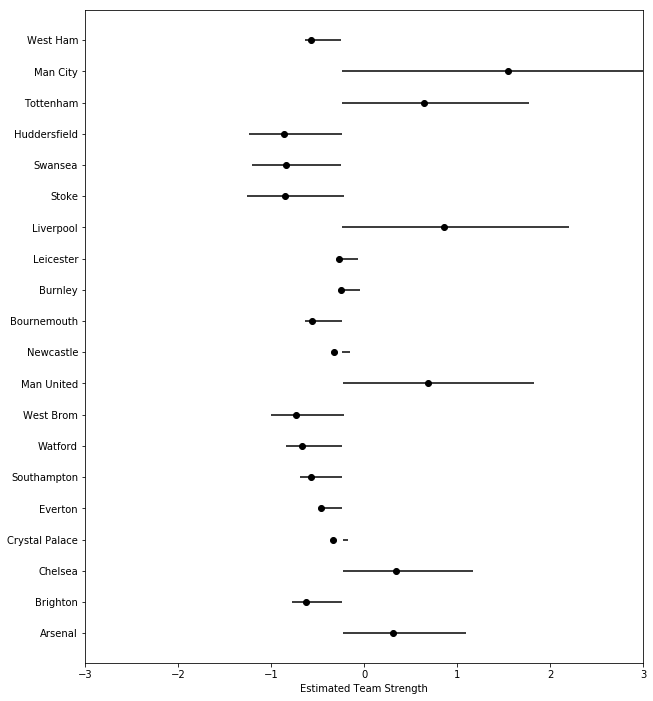
Looking at the estimated team ability after 38 games
fit_final = np.percentile(a_samps[:, 37, 0:20], q = [25, 50, 75], axis = 0)
x = fit_final[0]
y = np.linspace(-3, 3, len(Teams))
my_yticks = Teams
plt.figure(figsize = (10,12))
plt.yticks(y, my_yticks)
plt.errorbar(x,y, xerr = [list(fit_final[1]), list(fit_final[2])], fmt = 'ko')
#plt.xlabel('Estimated Home Advantage (log-odds scale)')
plt.xlim(-3,3)
plt.xlabel('Estimated Team Strength')
plt.show()
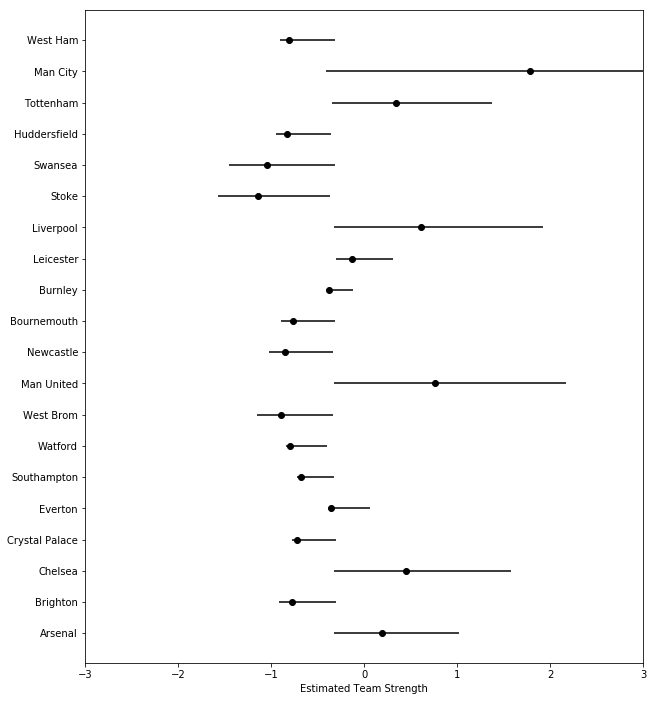
Looking at the estimated team abilities after 19 games (Half the season)
fit_init = np.percentile(a_samps[:, 18, 0:20], q = [25, 50, 75], axis = 0)
x = fit_init[0]
y = np.linspace(-3, 3, len(Teams))
my_yticks = Teams
plt.figure(figsize = (10,12))
plt.yticks(y, my_yticks)
plt.errorbar(x,y, xerr = [list(fit_init[1]), list(fit_init[2])], fmt = 'ko')
plt.xlabel('Estimated Team Strength')
plt.xlim(-3,3)
plt.show()
samples.keys()
odict_keys(['prev_coef', 'alpha', 'sigma_a0', 'tau_a', 'nu', 'sigma_scorediff', 'sigma_a_base', 'eta_a', 'a', 'sigma_a', 'score_diff_rep', 'lp__'])
samples['score_diff_rep'].shape
(1500, 380)
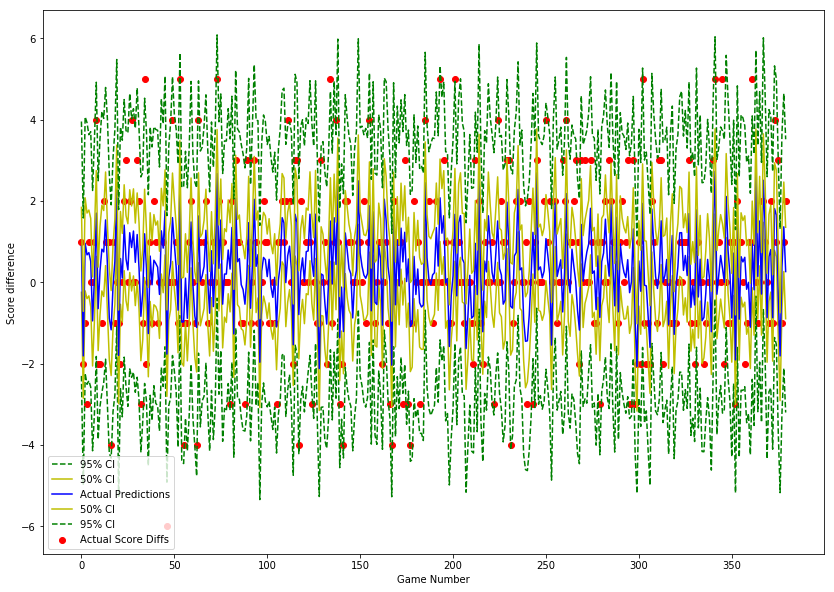
Evaluating how well calibrated our model is
The chart below shows the predicted score differences for all 380 games, along with 50% and 95% confidence intervals.
The red dots show the actual score differences. As you can see most of the actual scores lie well within the 50% confidence interval.
pred_scores = np.percentile(samples['score_diff_rep'], q = [2.5, 25, 50, 75, 97.5], axis = 0)
plt.figure(figsize = (14,10))
r1, = plt.plot(range(pred_scores.shape[1]),pred_scores[0], 'g--', label = '95% CI')
r2, = plt.plot(range(pred_scores.shape[1]),pred_scores[1], 'y-', label = '50% CI')
r3, = plt.plot(range(pred_scores.shape[1]),pred_scores[2], 'b-', label = 'predicted score diffs')
r4, = plt.plot(range(pred_scores.shape[1]),pred_scores[3], 'y-')
r5, = plt.plot(range(pred_scores.shape[1]),pred_scores[4], 'g--')
r6 = plt.scatter(range(pred_scores.shape[1]), data_dict['score_diff'], c = 'r')
plt.xlabel('Game Number')
plt.ylabel('Score difference')
plt.legend([r1, r2, r3, r4, r5, r6], ['95% CI', '50% CI', 'Actual Predictions', '50% CI', '95% CI', 'Actual Score Diffs'], loc = 'lower left')
<matplotlib.legend.Legend at 0x1a2081bb00>